Martingale posteriors in modern AI
Trial Lecture, University of Oslo
2025-11-28
LLM In-Context Learning
- Assume we ask an LLM to solve the following problem
- Collect some few shot examples
- Let the LLM generate additional examples
- Repeat and record answer
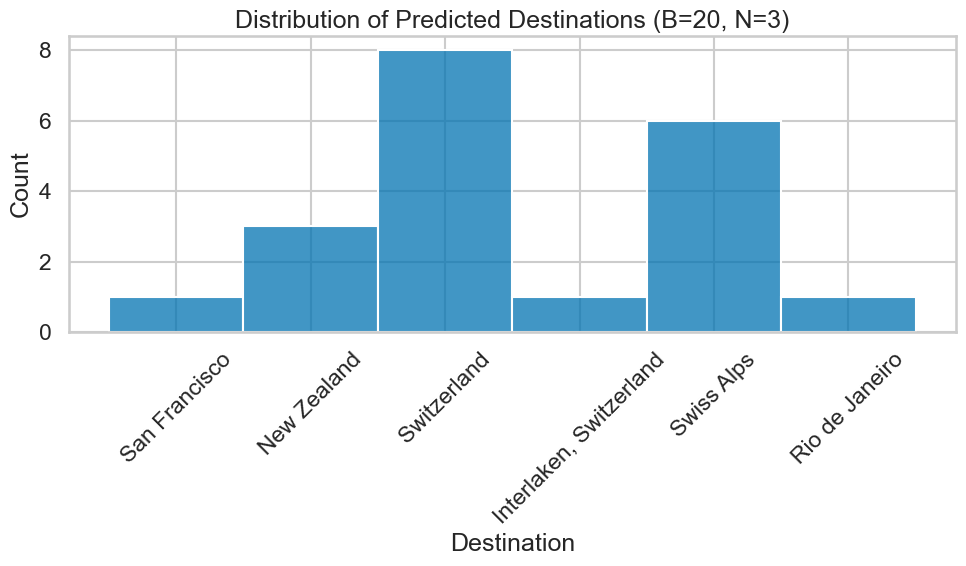
Where should this person go on holiday based on some information of that person?x: Anders is a physicist and likes to discuss philosophy
y: destination=Rome
x: Kamilla enjoys skiing and works at the local university
y: destination=Alpsx: Maria is retired and spends her time gardening and traveling
y: destination=Madeira
x: Sven just quit his job and is now playing in a band with his friends.
y: destination=Nashville
x: Elias is in military conscription and is considering studying engineering afterward
y: destination=Berlin
x: Ingrid is a medical resident finishing her fourth year of specialty training
y: destination=The Well
x: Thomas just became a partner at a consulting firm and enjoys sailing
y: destination=Maldivesx: Simen just defended his PhD in Machine Learning and enjoys paragliding
y:Valid? Posterior predictive?
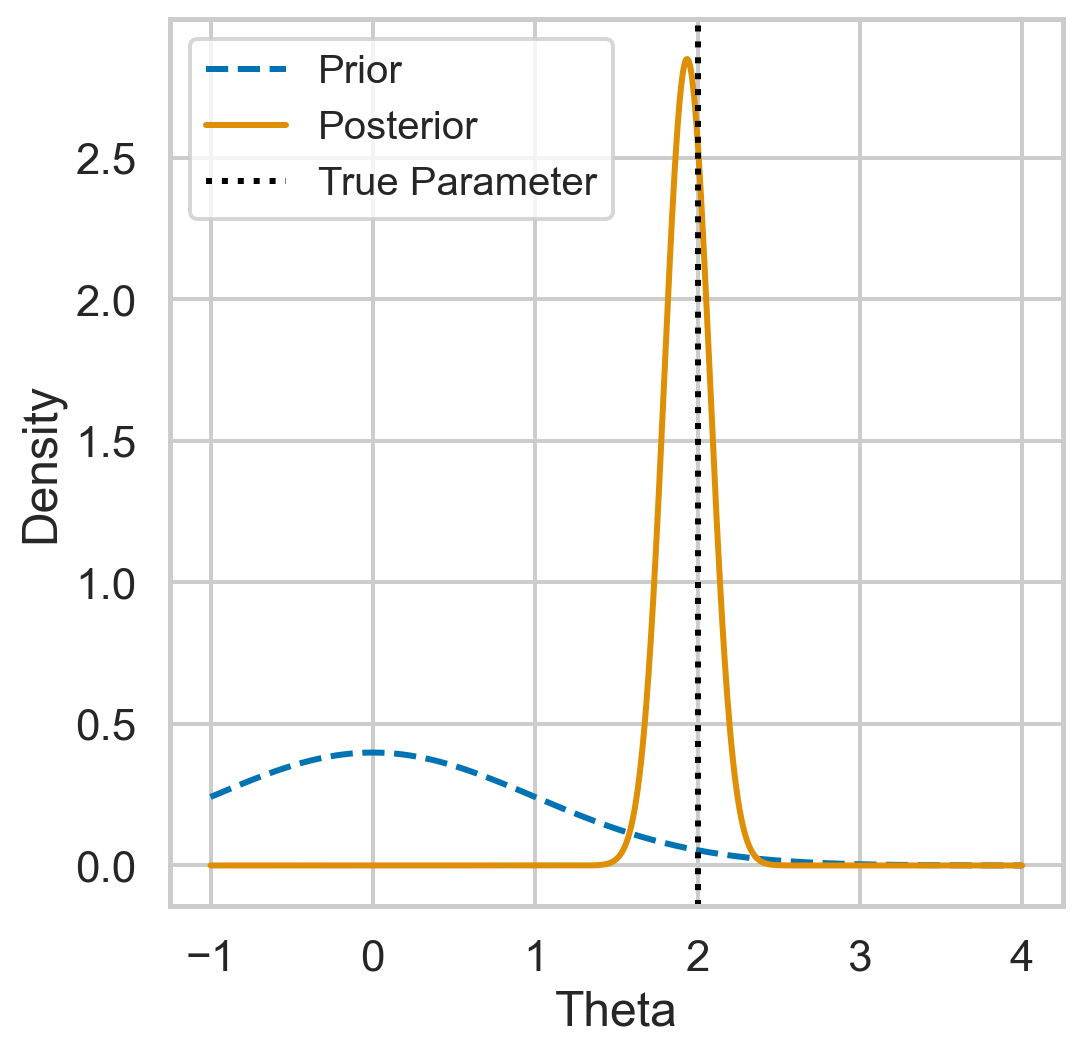
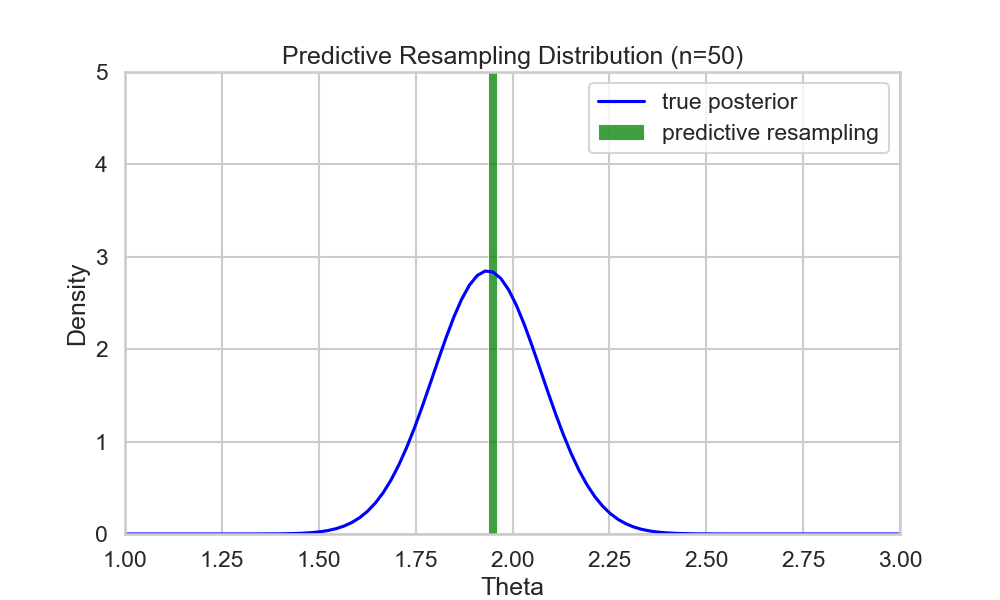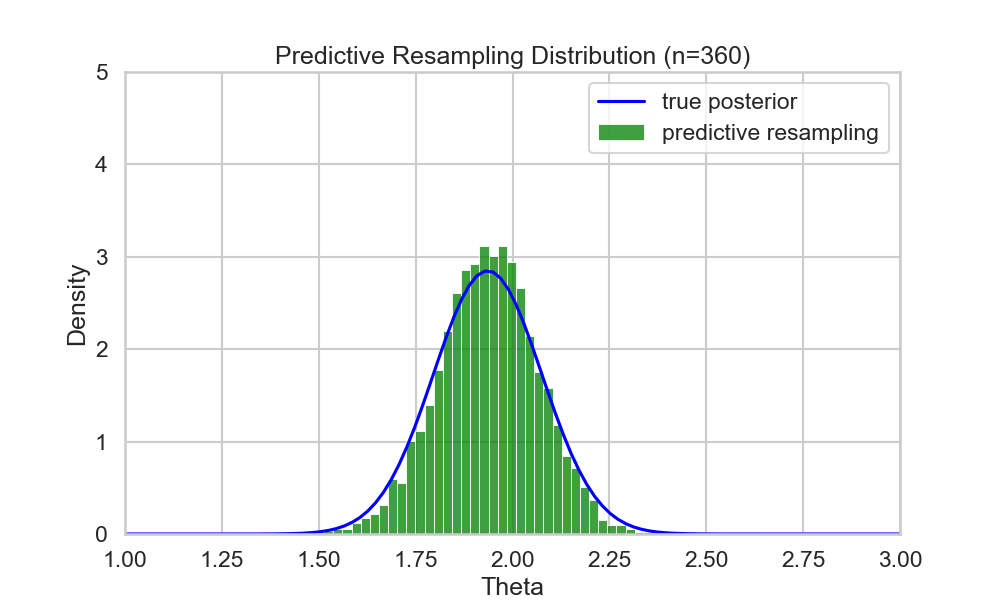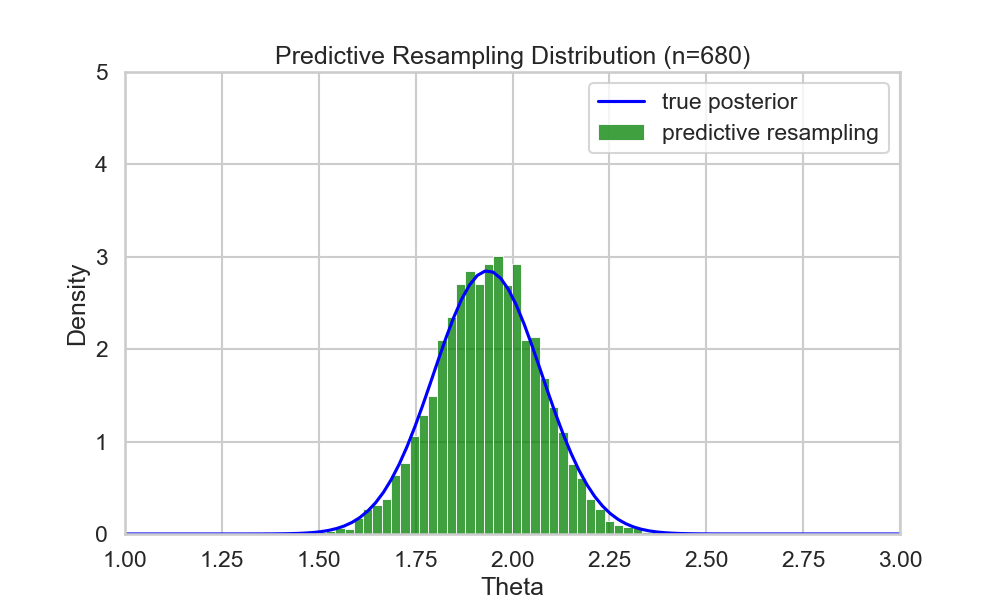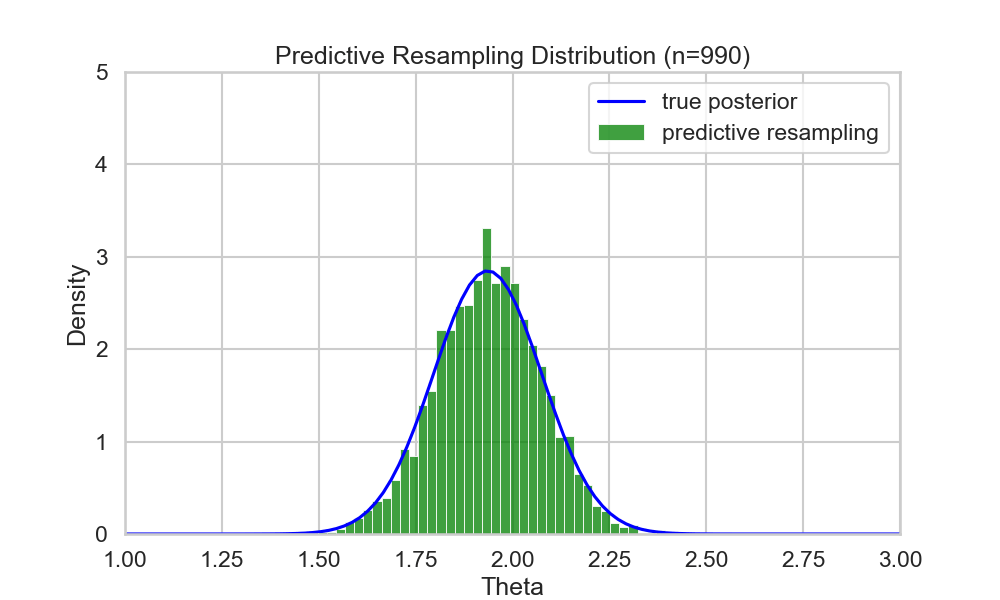
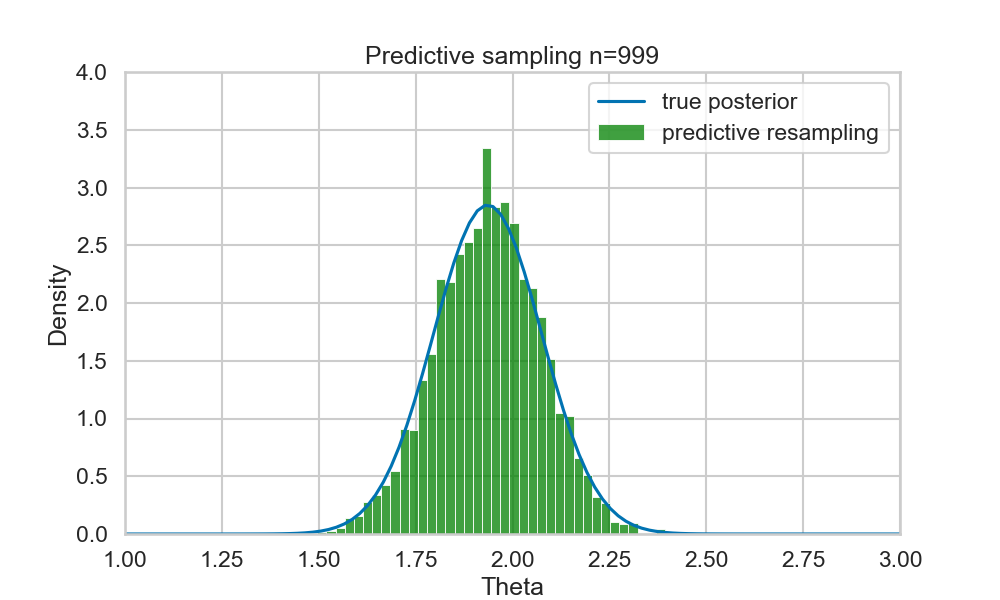
Example (run predictive resampling)
- Let the predictive distribution be the true posterior predictive: \[ P(y_{i+1} | y_{1:i}) = N(y | \bar{\theta_i}, \bar{\sigma_i^2} + 1)\]
- Step 1: For \(i=n,...,N-1\): Sample \(y_{i+1} | y_{1:i}\) from the posterior predictive
- Step 2: Compute the point estimate of \(\theta\) given the full data \(y_{1:N}\): \[ \hat{\theta}(y_{1:N}) = \frac{\sum_{i=1}^N y_i}{N+1} \]
- Repeat B times to get posterior samples of \(\theta\)

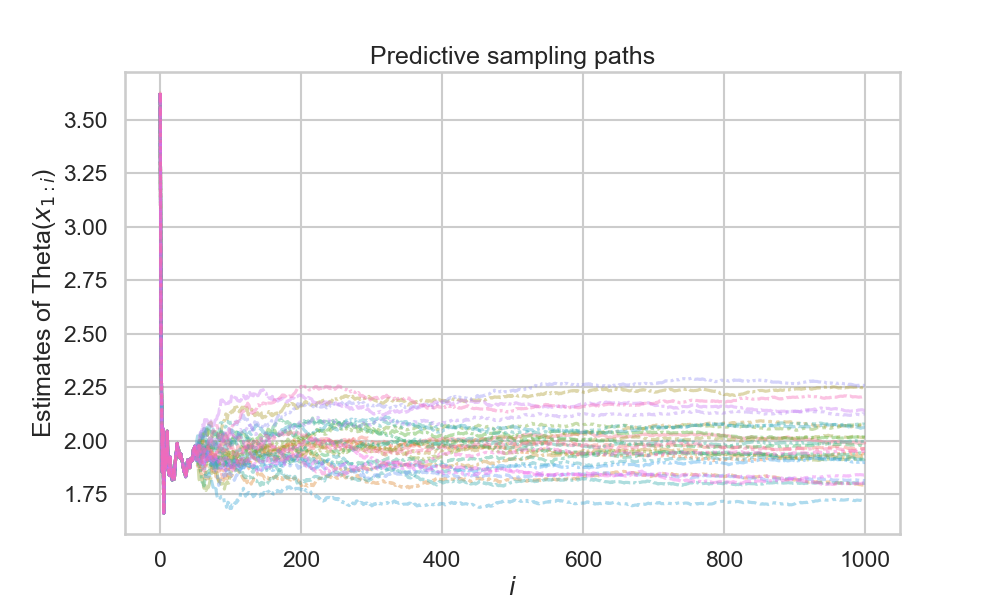
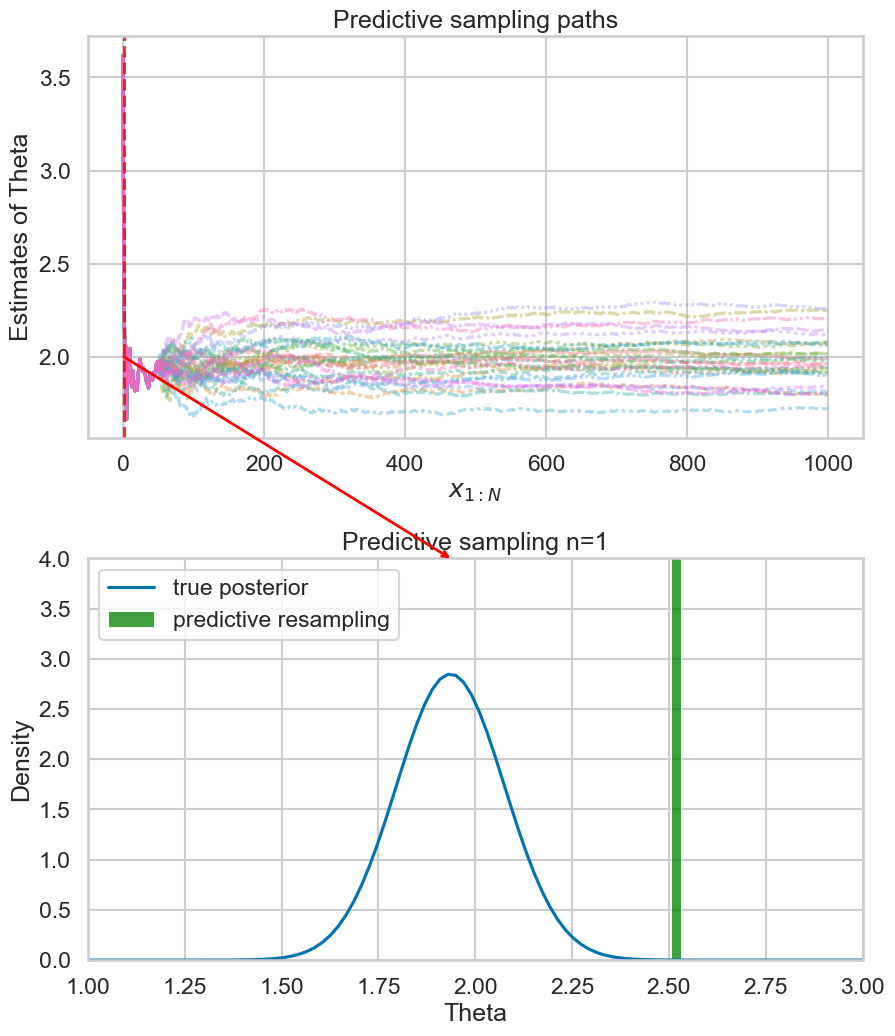
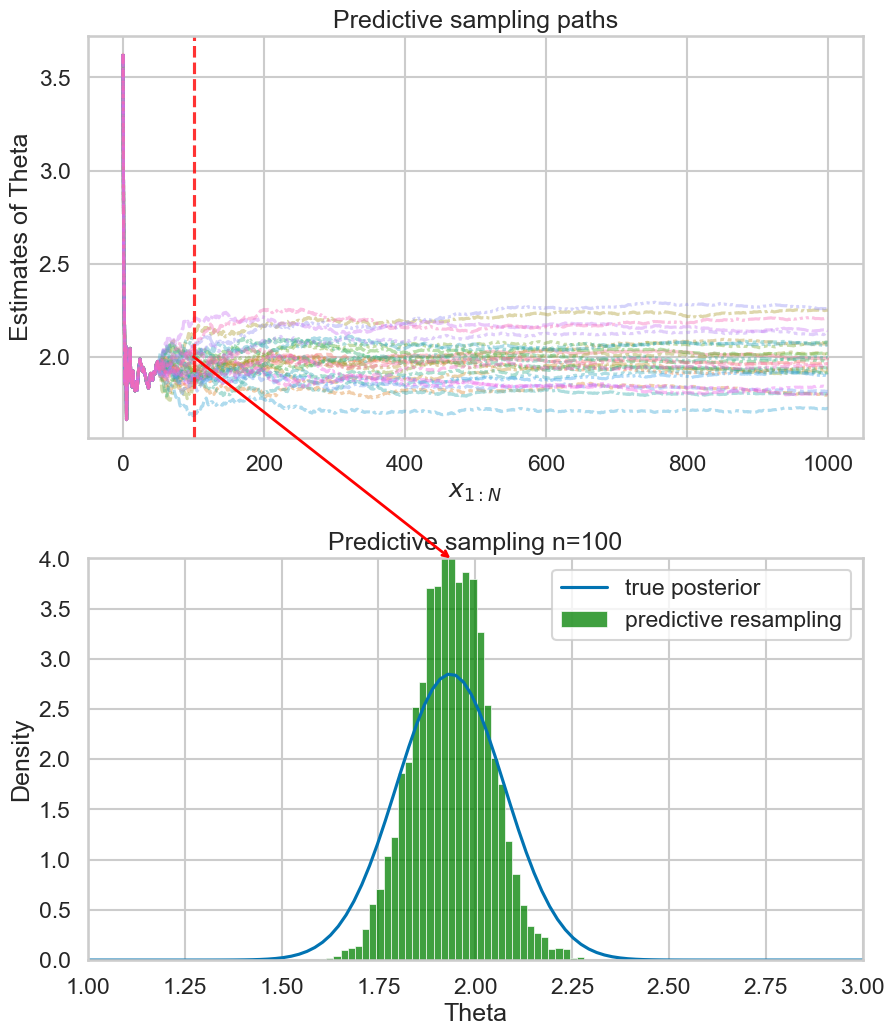
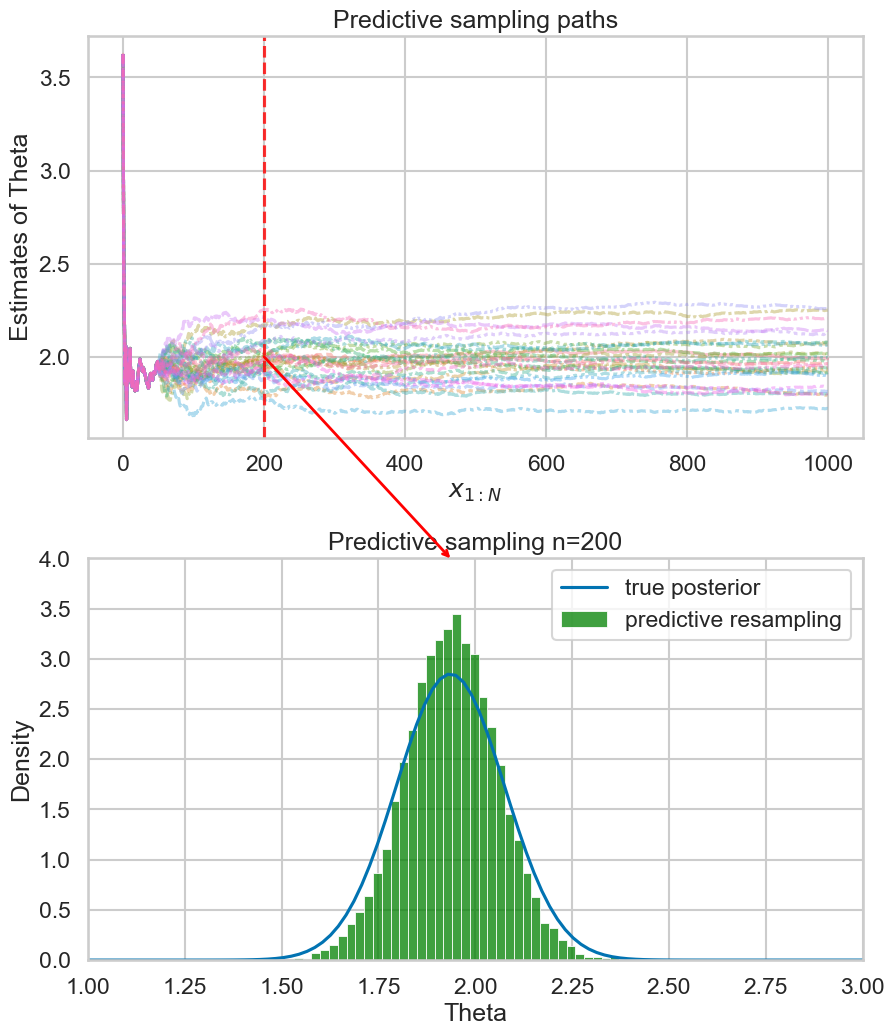
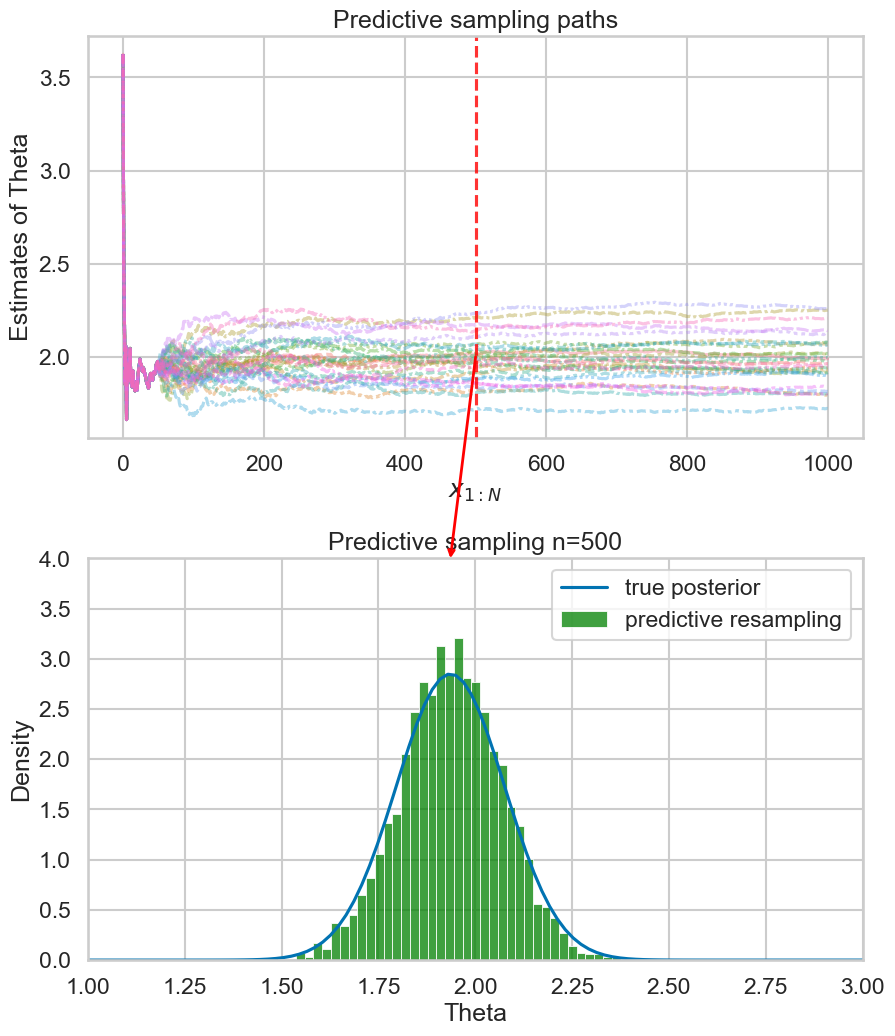
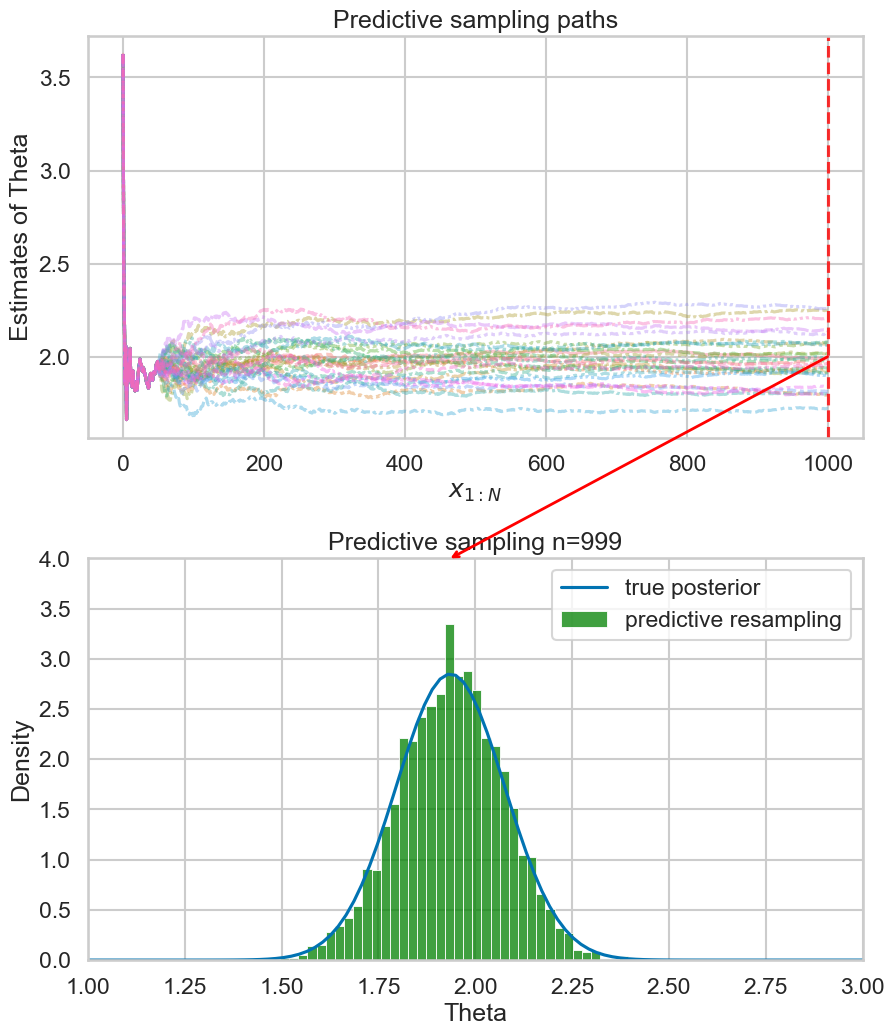
Example 1: Empirical predictive
- Remember example:
- \(Y_i \sim N(\theta, 1)\)
- \(\theta=2\)
- If we instead of the true posterior predictive assume an empirical predictive on the collected data \(y_{1:n}\):
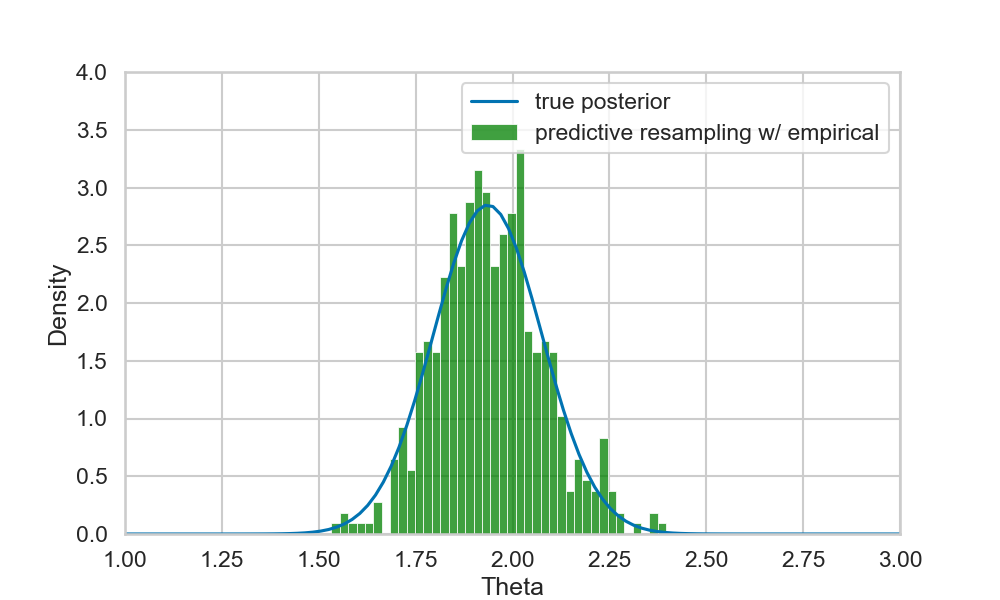
- Works but “worse model”
Are LLMs martingales?
- Check whether \(P(y_{i+1}|y_{1:i})\) is a martingale
- Note: \(y_{i+1}\) is not the next token!
Where should this person go on holiday based on some information of that person?x: Anders is a physicist and likes to discuss philosophy
y: destination=Rome
x: Kamilla enjoys skiing and works at the local university
y: destination=Alpsx: Maria is retired and spends her time gardening and traveling
y: destination=Madeira
x: Sven just quit his job and is now playing in a band with his friends.
y: destination=Nashville
x: Elias is in military conscription and is considering studying engineering afterward
y: destination=Berlin
x: Ingrid is a medical resident finishing her fourth year of specialty training
y: destination=The Well
x: Thomas just became a partner at a consulting firm and enjoys sailing
y: destination=Maldivesx: Simen just defended his PhD in Machine Learning and enjoys paragliding
y:Are LLMs martingales?
Falck, Wang, and Holmes (2024)
- Falck, Wang, and Holmes (2024) studies martingale property of LLMs in-context learning empirically
- Tests three LLMs:
gpt-3.5,llama-2-7bmistral-7b
- Tests three datasets:
- Bernoulli,
- Gaussian,
- Synthetic natural language dataset
- Result: No.
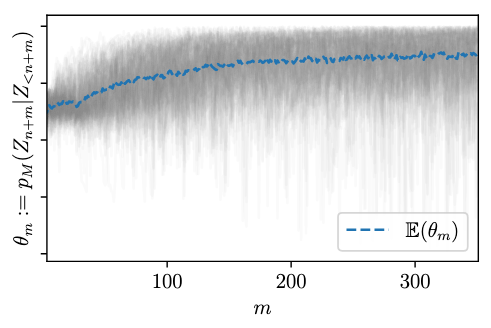
- The expected probability drifts as \(i\) increases
- Suggests tools or fine tuning to make LLMs more like martingales